Azure Local - Kubernetes - Part 7 - Deploy Foundry Local (Preview) on Azure Local
- Intro
- Prerequisites
- Step 1 — Browse the marketplace tile
- Step 2 — Create an Entra ID application for the operator
- Step 3 — Install the cert-manager extension (prerequisite)
- Step 4 — Deploy the Foundry Local extension
- Step 5 — Browse the model catalogue
- Step 6 — Deploy a model
- Step 7 — Get the API key and reach the endpoint
- Step 8 — Verify the model is healthy from inside the pod
- Step 9 — Call the chat completions API
- Troubleshooting — from nginx
- Final remark
Intro
This article is part of a series: Navigate to series page
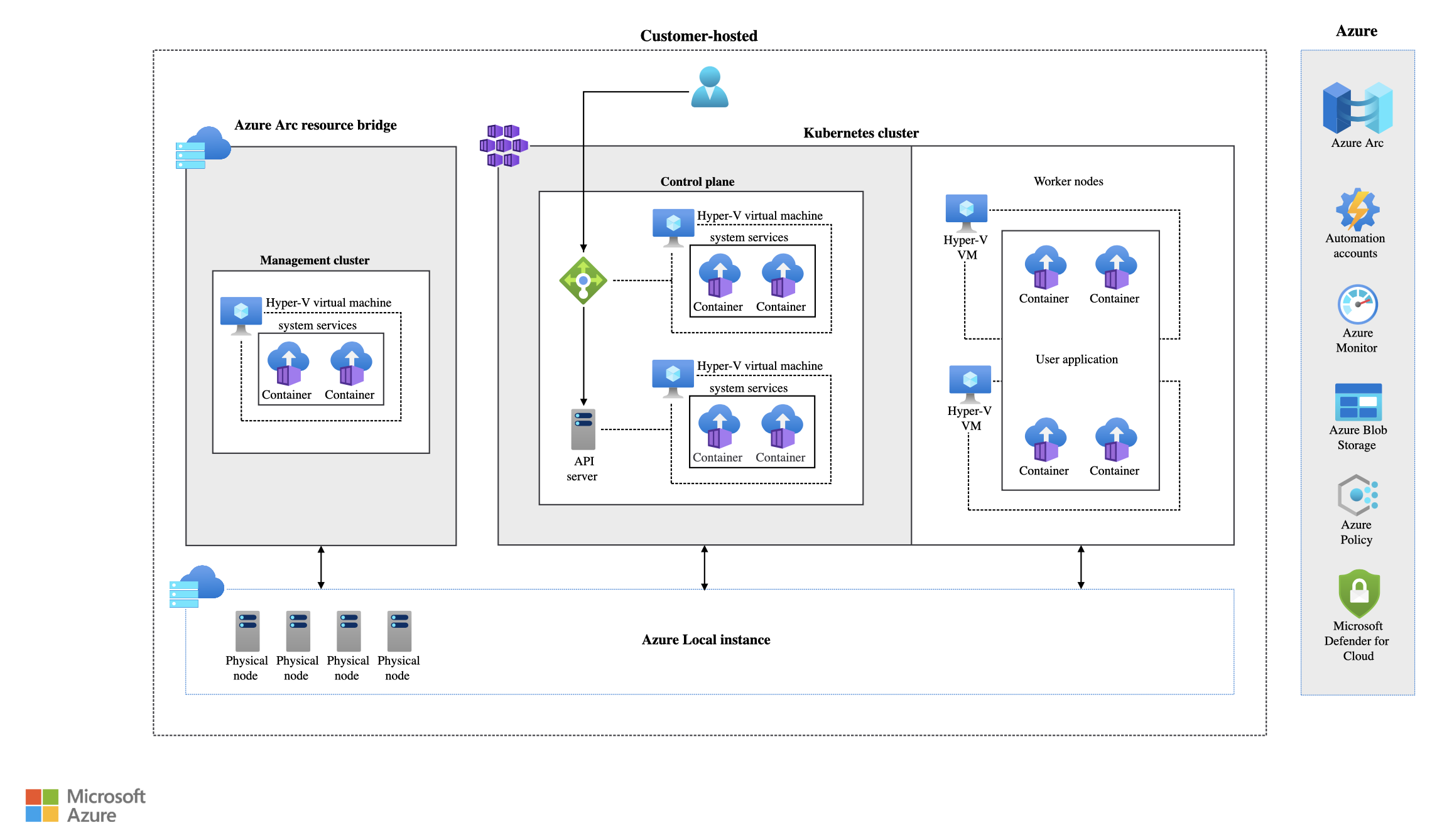
Foundry Local on Azure Local (Preview) brings the Foundry model runtime to your on-premises Kubernetes cluster on Azure Local. You deploy a Kubernetes extension (microsoft.foundry) that provisions an inference operator into your cluster, and from there you can deploy curated models from the Foundry catalogue as ModelDeployment custom resources. The models run as pods next to your other workloads, expose an OpenAI-compatible /v1/chat/completions endpoint, and are protected with an API key.
In this article I will walk through everything I did to get Foundry Local up and running on top of an AKS Arc cluster I deployed earlier in this series (Part 1 - Deploy Kubernetes cluster on Azure Local). I will also share the troubleshooting I went through when my first model would not respond and the API returned 504 Gateway Time-out from nginx.
Prerequisites
Before you start, make sure the following is in place:
- An Azure Local cluster with a healthy Kubernetes cluster deployed and Arc-connected. In my case the cluster is
azlckj5-k8sin resource grouprg-weu-ckj-prod. kubectlconfigured against the cluster — see Part 2 - Connect to Kubernetes cluster.- The
k8s-extensionAzure CLI extension. If you do not have it, the CLI will prompt to install it dynamically the first time you run anaz k8s-extensioncommand. - Your subscription must be enabled for the gated Foundry Local on Azure Local (Preview) offer. There is an Application for Gated Services link in the marketplace tile — fill it out if you have not been granted access yet.
Step 1 — Browse the marketplace tile
Navigate to the Kubernetes cluster resource in the Azure Portal, go to Settings → Extensions, and click + Add.
![]()
In the marketplace search for Foundry Local, you will find the tile Foundry Local on Azure Local (Preview) published by Microsoft.
Open the tile, select your subscription and plan, and click Create.
HINT
If your subscription is not yet enabled for the preview, the Create wizard will show a banner pointing to the Application for Gated Services form. Submit it and wait for the approval before continuing.
Step 2 — Create an Entra ID application for the operator
The Foundry Local extension uses Microsoft Entra ID to authenticate calls to the inference operator API. Before deploying the extension you need an Entra application (app registration) and its Application (client) ID and the Directory (tenant) ID.
I created a new app registration named azlckj5-k8s-foundry-local in my tenant. Take note of the client ID and tenant ID — you will need both in the next step.
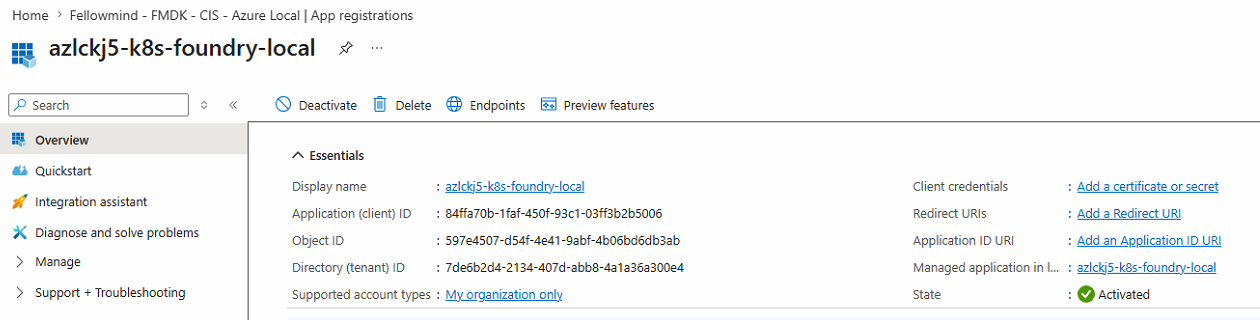
In my case:
- Tenant ID:
7de6b2d4-2134-407d-abb8-4a1a36a300e4 - Client ID:
84ffa70b-1faf-450f-93c1-03ff3b2b5006
Step 3 — Install the cert-manager extension (prerequisite)
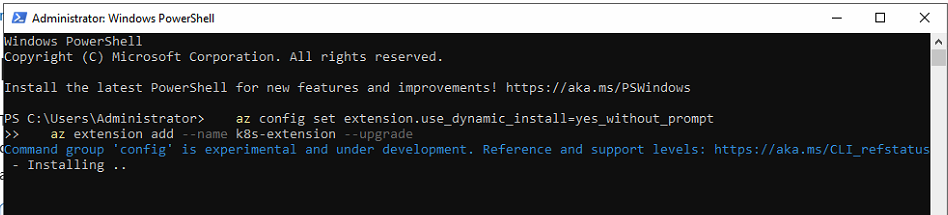
The Foundry Local extension depends on cert-manager and trust-manager being available in the cluster for the operator’s webhook certificates. I installed it via the Azure CLI:
az k8s-extension create `
--cluster-name "azlckj5-k8s" `
--name "azure-cert-manager" `
--resource-group "rg-weu-ckj-prod" `
--cluster-type connectedClusters `
--extension-type Microsoft.CertManagement `
--scope cluster `
--release-train stable `
--config config.enableGatewayAPI=true `
--config cert-manager.crds.keep=true `
--config trust-manager.defaultPackage.enabled=false `
--config trust-manager.secretTargets.enabled=true `
--config trust-manager.secretTargets.authorizedSecretsAll=trueBecause this extension type is a preview, the CLI will prompt to allow dynamic installation of the k8s-extension CLI extension and to enable preview-versioned extensions. Answer y to both prompts.
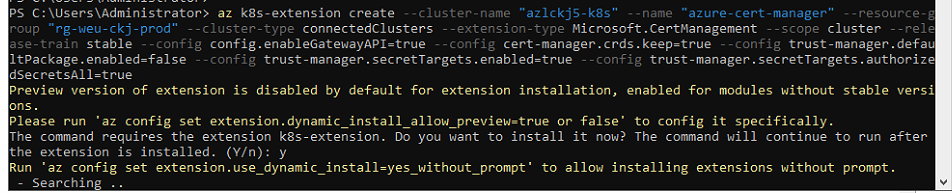
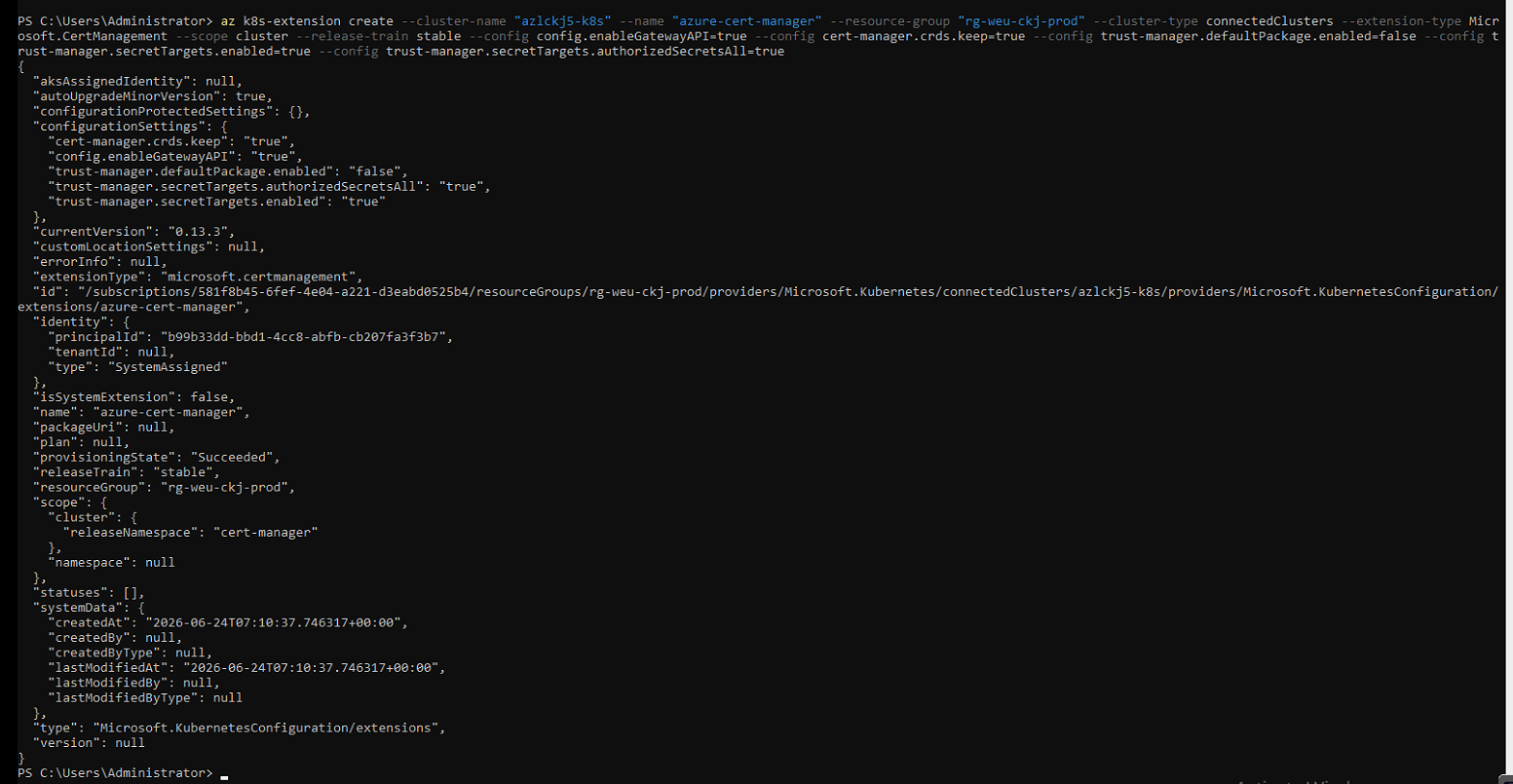
After a few minutes the deployment returns with provisioningState: Succeeded.
Step 4 — Deploy the Foundry Local extension
You can either continue through the portal wizard from Step 1 or use the Azure CLI. I show both here, but I ended up using the CLI because it gave me direct control over the operator’s worker count and memory limit — which mattered later (see the troubleshooting section).
Option A — Portal wizard
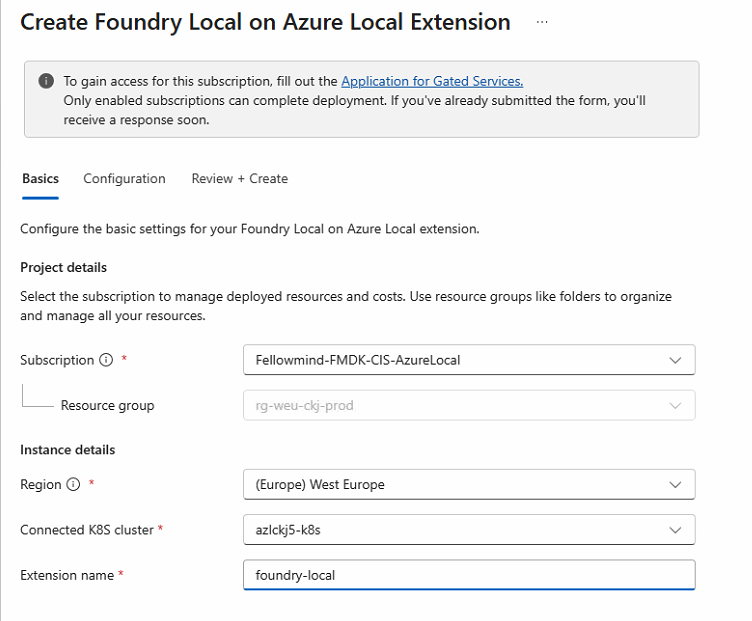
On the Basics tab, set the subscription, region, the connected K8s cluster, and the extension name.
On the Configuration tab, enable Microsoft Entra ID and paste in the Entra application ID from Step 2. The Kubernetes namespaces field is optional — if left blank, models can only be deployed to the foundry-local-operator namespace.
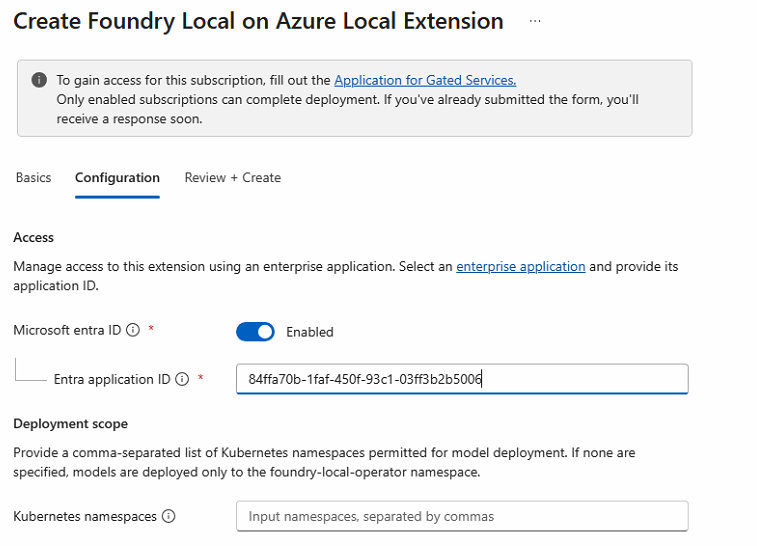
On Review + create, verify the summary and click Create.
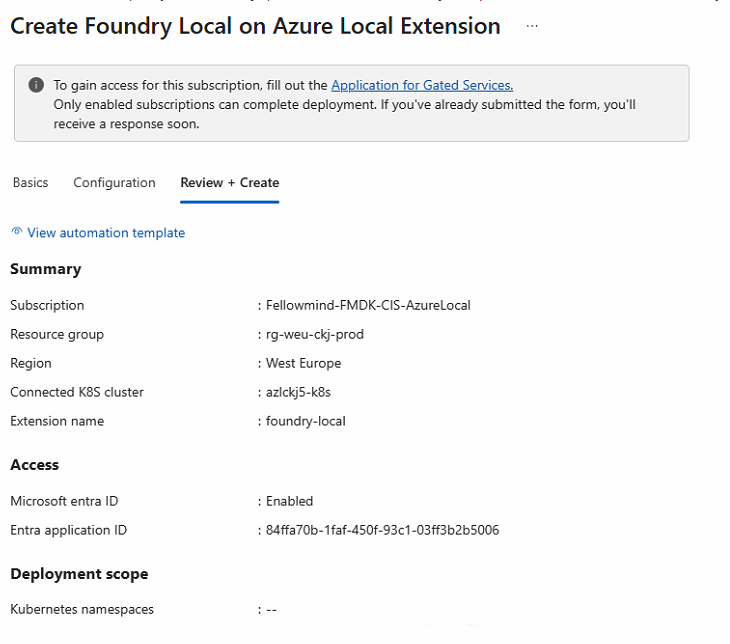
Option B — Azure CLI
This is what I actually deployed in the end, with the operator API tuned to 1 worker and a 2 GiB memory limit (more on why under troubleshooting):
UPDATE
Update: 28-06-2026 Microsoft informs they have fixed the issue in their June 2026 update, so defining workers and memory limit should not be needed anymore
az k8s-extension create `
--resource-group "rg-weu-ckj-prod" `
--cluster-name "azlckj5-k8s" `
--name "inference-operator" `
--extension-type Microsoft.Foundry `
--scope cluster `
--release-namespace "foundry-local-operator" `
--cluster-type connectedClusters `
--auto-upgrade-minor-version true `
--release-train stable `
--config entraAuth.tenantId="7de6b2d4-2134-407d-abb8-4a1a36a300e4" `
--config entraAuth.clientId="84ffa70b-1faf-450f-93c1-03ff3b2b5006" `
--configuration-settings api.config.server.workers=1 `
--configuration-settings api.resources.limits.memory=2G
After a few minutes the extension shows as Succeeded in the portal:

HINT
The
--release-namespacecontrols where the operator itself runs. The defaultfoundry-local-operatornamespace is also where you will deploy yourModelDeploymentresources unless you explicitly add more namespaces via the extension configuration.
Step 5 — Browse the model catalogue
The operator exposes the curated Foundry model catalogue through the cluster. You can inspect it via kubectl to see what is available and which compute / execution providers each model requires:
kubectl get modelcatalog -n foundry-local-operator -o jsonFor example, here is the entry for qwen3-0.6b-generic-cpu — a CPU-friendly Qwen3 0.6B model packaged for ONNX:
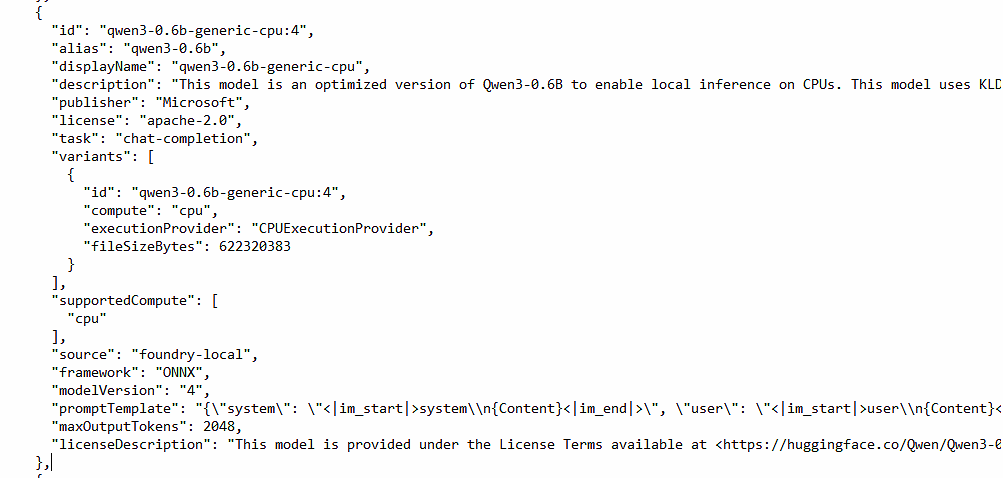
The important fields are compute (cpu or gpu), executionProvider (e.g. CPUExecutionProvider), and fileSizeBytes — useful for sizing the worker node before scheduling the pod.
Step 6 — Deploy a model
A model is deployed by applying a ModelDeployment custom resource. I started with the small Qwen3 0.6B CPU variant. Save the following as model-deployment.yaml:
apiVersion: foundrylocal.azure.com/v1
kind: ModelDeployment
metadata:
name: qwen3-0-6b-generic-cpu
namespace: foundry-local-operator
spec:
model:
catalog:
name: qwen3-0.6b-generic-cpu
version: "latest"
compute: cpu
runtime: onnx-genai
workloadType: generative
replicas: 1
port: 5000
skipGpuResource: true
nodeSelector:
kubernetes.io/os: linux
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "2"
memory: "4Gi"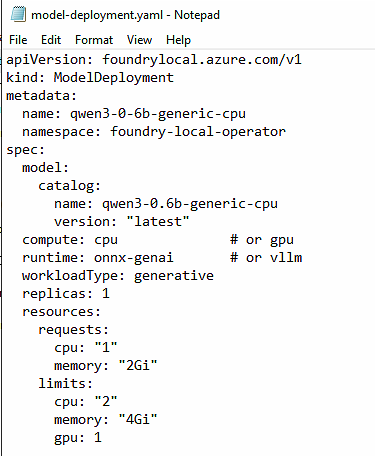
Apply it:
kubectl apply -f model-deployment.yaml
After the operator pulls the model files and the pod becomes ready, the ModelDeployment shows STATE: Running and READY: true:
kubectl get modeldeployment "qwen3-0-6b-generic-cpu" -n foundry-local-operator
Step 7 — Get the API key and reach the endpoint
Each ModelDeployment gets a dedicated Kubernetes Service and a generated API key stored in a Secret. To talk to the model from my workstation I port-forward the service to localhost:
kubectl port-forward svc/qwen3-0-6b-generic-cpu -n foundry-local-operator 5000:5000
Then fetch and base64-decode the API key:
$secret = kubectl get secret qwen3-0-6b-generic-cpu-api-keys -n foundry-local-operator -o jsonpath="{.data.primary-key}"
[System.Text.Encoding]::UTF8.GetString([System.Convert]::FromBase64String($secret))
Step 8 — Verify the model is healthy from inside the pod
Before invoking the model from outside, it is worth confirming that the inference container itself is healthy. Exec into the pod and hit the local /v1/models and /health endpoints directly — this bypasses the nginx sidecar so you know whether any later 5xx is a backend issue or a fronting/ingress issue:
kubectl get pod -n foundry-local-operator -l app.kubernetes.io/name=qwen3-0-6b-generic-cpu
kubectl exec -n foundry-local-operator qwen3-0-6b-generic-cpu-f6fbd6996-k7nts -c inference -- curl -s http://127.0.0.1:5000/v1/models
kubectl exec -n foundry-local-operator qwen3-0-6b-generic-cpu-f6fbd6996-k7nts -c inference -- curl -s http://127.0.0.1:5000/health
In my case the backend returned {"status":"healthy"} and the model was listed correctly — so the model itself was fine.
Step 9 — Call the chat completions API
With the port-forward still running and the decoded API key in hand, call the OpenAI-compatible endpoint with PowerShell. The certificate is self-signed at this stage, so -SkipCertificateCheck is required:
$headers = @{ "api-key" = "YOUR-API-KEY-HERE>" }
$body = @{
model = "qwen3-0-6b-generic-cpu"
messages = @(@{ role = "user"; content = "Say hi briefly." })
max_tokens = 16
} | ConvertTo-Json -Depth 10
$response = Invoke-RestMethod -SkipCertificateCheck `
-Uri "https://127.0.0.1:5000/v1/chat/completions" `
-Method Post -Headers $headers -ContentType "application/json" `
-Body $body -TimeoutSec 900
$response.choices[0].message.contentThis is where things got interesting. Read on.
Troubleshooting — 504 Gateway Time-out from nginx
My first attempts against qwen3-0-6b-generic-cpu failed with a 504 Gateway Time-out returned by the nginx fronting the model pod, even though /health inside the inference container reported healthy:
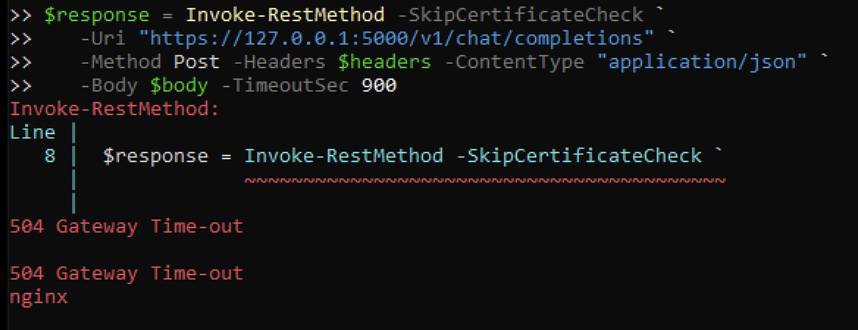
After digging into the pods I narrowed it down to the inference-operator API itself, not the model. The operator API was starting with 4 gunicorn workers (default), which on my small node pool was causing the API container to repeatedly hit its memory limit and get OOM-killed mid-request. The model pod was healthy, but the operator-managed nginx in front of it could not complete the upstream call within the timeout window, and returned 504.
The symptoms were:
kubectl get rs -n foundry-local-operatorshowed a stuck rollout — a new ReplicaSet forinference-operator-apiwas scheduled but never reached ready, and the old ReplicaSet stayed up.- Trying to patch the deployment in-place with
kubectl set env deployment/inference-operator-api WORKERS=1andkubectl rollout restartdid not help, because the extension reconciler kept re-creating the old ReplicaSet from its desired state.
Root cause
The default configuration of the Microsoft.Foundry extension provisions the inference operator API with 4 workers and a memory limit that is too tight to safely run all 4 on a small worker node. Because the extension is reconciled by Arc, any manual changes to the underlying deployment are reverted.
Solution
Set the operator’s worker count and memory limit through the extension’s configuration-settings instead of patching the deployment. Since the extension was already deployed with defaults, I deleted and re-created it:
az k8s-extension delete `
--name inference-operator `
--resource-group "rg-weu-ckj-prod" `
--cluster-name "azlckj5-k8s" `
--cluster-type connectedClusters
az k8s-extension create `
--resource-group "rg-weu-ckj-prod" `
--cluster-name "azlckj5-k8s" `
--name "inference-operator" `
--extension-type Microsoft.Foundry `
--scope cluster `
--release-namespace "foundry-local-operator" `
--cluster-type connectedClusters `
--auto-upgrade-minor-version true `
--release-train stable `
--config entraAuth.tenantId="7de6b2d4-2134-407d-abb8-4a1a36a300e4" `
--config entraAuth.clientId="84ffa70b-1faf-450f-93c1-03ff3b2b5006" `
--configuration-settings api.config.server.workers=1 `
--configuration-settings api.resources.limits.memory=2GAfter the extension finished provisioning, I redeployed the model with the same model-deployment.yaml. To rule out qwen3 itself I also tried qwen2.5-0.5b-instruct-generic-cpu — same manifest, different catalog name:
apiVersion: foundrylocal.azure.com/v1
kind: ModelDeployment
metadata:
name: qwen2-5-0-5b-instruct-generic-cpu
namespace: foundry-local-operator
spec:
model:
catalog:
name: qwen2.5-0.5b-instruct-generic-cpu
version: "latest"
compute: cpu
runtime: onnx-genai
workloadType: generative
replicas: 1
port: 5000
skipGpuResource: true
nodeSelector:
kubernetes.io/os: linux
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "2"
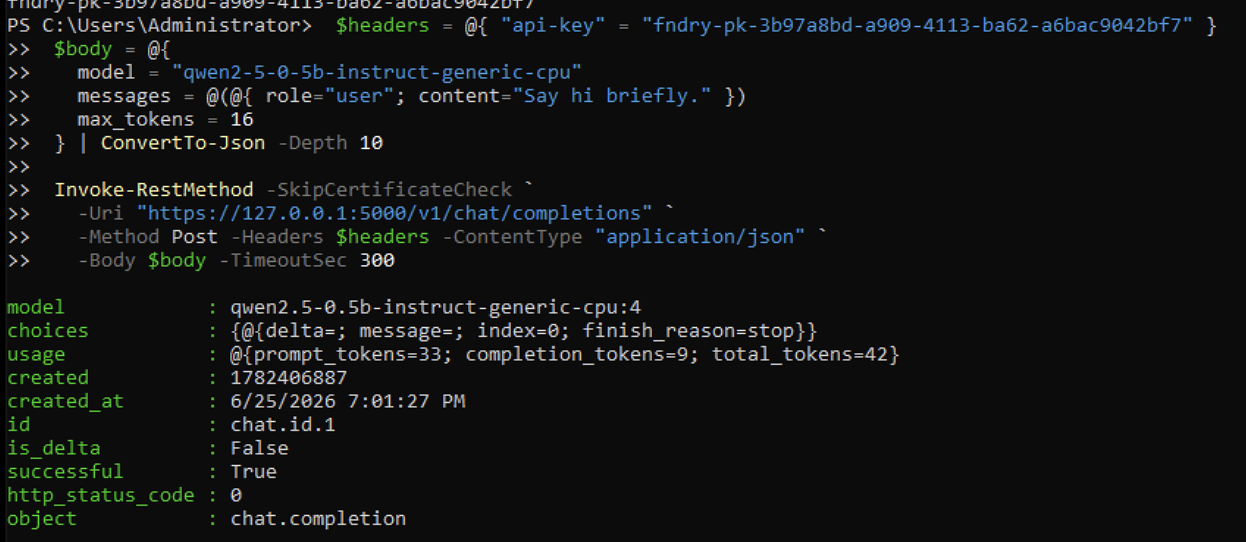
memory: "4Gi"The first invocation came back successful — successful : True, http_status_code : 0, object : chat.completion — but the content was empty because I only gave it 16 tokens to play with:
Giving it a slightly longer prompt and printing the message content returned the expected response:
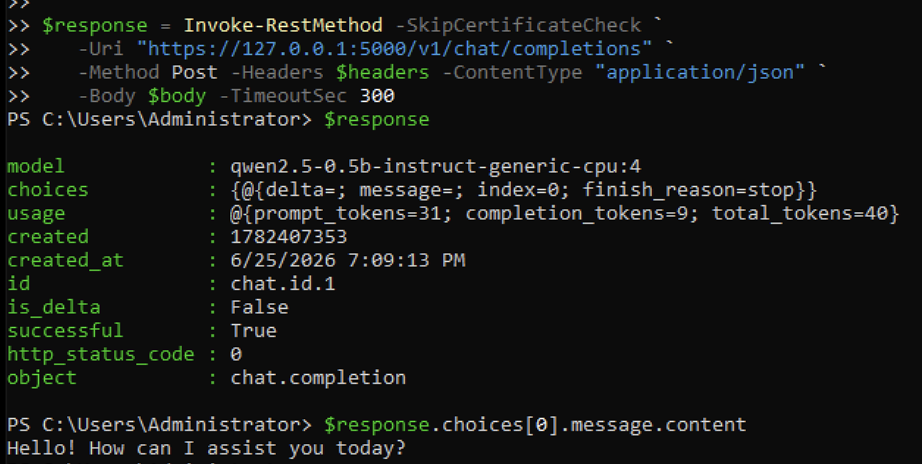
Hello! How can I assist you today?I did hit the 504 gateway time-out error on this model also, so overall my lab setup should allow for the model to consume more CPU and memory - but running this on nested virtualization with very old hardware was not expected to perform very well.
Final remark
Two takeaways from this exercise:
- Always set
api.config.server.workersandapi.resources.limits.memoryon theMicrosoft.Foundryextension when you create it. Editing the deployment afterwards is fighting the Arc reconciler — you will lose. Delete and re-create the extension with the right--configuration-settingsinstead. - Test the backend inside the pod first with
kubectl exec ... curl http://127.0.0.1:5000/health. If/healthis fine but the external call returns 504, the problem is almost always between the operator API and the model pod (resource pressure on the operator, nginx upstream timeout, or a stuck rollout) — not the model itself.
Foundry Local on Azure Local is still preview, but once these knobs are tuned it gives you a clean way to run small open models on your own hardware with an OpenAI-compatible API — no traffic ever leaves the cluster.
Have feedback on this post?
Send me a message and I'll get back to you.